

Article Table of Content
- What is a Search Engine?
- Why Do People Use Search Engines?
- The 3 Stages of a Search Engine
- 1. Crawling: Finding Pages on the Web
- 2. Indexing: Cataloging and Storing Info
- 3. Retrieval: Returning Relevant Results
- How Does SEO Fit In?
- The Evolution of Search Engines
- The Most Popular Search Engines
- How Many Websites are on the Web?
- How Can I Learn More About Search Engines
What is a Search Engine?
Have you ever wondered “How do search engines work?”. In this article, I will attempt to answer that question as well as how search engines such as Google manage to keep track of all of those websites.
Why Do People Use Search Engines?
You need information, you need it to be relevant and you need it now. What do you do? If you’re like most people these days, you turn to a search engine, such as Google.com. A search engine is a tool designed to search for information on the World Wide Web.

Allow me this example: You get on your computer, open up your browser and type in the web address of your favorite search engine. For some that would be Google, or Yahoo! or Bing, these are the top three search engines in the United States.
You then type in a word or a phrase of whatever you are looking for, press the enter button and the search engine returns a list of results. These results are usually presented to you as a list of websites, pictures, videos and might even include a map.
You are then left with the choice of searching through the list to choose the information or item you want.
Search Engines are Simple Yet Complicated
In its basic form a search engine is a website located on the Internet that you can use to find information about something. That something could basically be anything: person, place or thing.
On the surface all you see is the home page, referred to in computer terms as the user interface and the list that is returned to you, A.K.A as the search results. However, behind the scenes there is so much at work.
How Often Do People Use Search Engines?
Tens of millions of people perform searches just like this 24 hours a day, all over the world but don’t have a clue how the website they trust to provide them information does it. Most don’t care and frankly, don’t need to know but if you are curious, let me help you out.
The 3 Stages of a Search Engine
The process that search engines use to collect information can be define in what I like to call the Three Search Engine Stages:
- Crawling – The process of discovering the content of web pages
- Indexing – The process of analyzing, cataloging and storing web pages
- Retrieval – The process providing relevant results during visitor search queries
#1. Crawling: Finding Pages on the Web
How Do Search Engines Find and Collect Information?
Search engine use special programs called Robots to crawl the Internet looking for new web pages of a website. Robots have also been called bots or spiders. One of the ways that robots accomplish their crawling process is through the use of links on a web page. Links act as a pathway to a website from another website.
Although Google and the other search engines will eventually discover your website without you needing to do anything, the best way to speed up the process is by using discovery tools such as the Google Search Console (The GSC), formerly Google Webmaster Tools.
Whether the search engines automatically discover your site or through their submission tools, they as a next step crawl and analyze the content, other coding, and links on your web pages.
By doing this a search engine can catalog your website and figure out what your site is all about. This is all part of what’s referred to as the indexing process.
#2. Indexing: Cataloging and Storing Info
What’s this Index Stuff?
An index is kind like the table of contents of a book, it contains all of the content, links and references for all the web pages it finds during a scan (or search) of the of the Internet. A search engine constantly indexes millions of pages a day.
Most people think that when they are performing a search in Google, Yahoo or Bing that they are searching the web, when actually, they are in fact only being provided a copy within the search results that’s from an index or database. Now keep in mind that this index may contain billions of web pages at any one time. (betcha didn’t know that!)
Since each search engine uses its own set of algorithms to search through the indices, this will usually produce similar, but different results listings and rankings. The the algorithms also analyze the way that pages link to other pages on the Internet.
By checking how pages link to each other, an engine can determine what a page is about and, if the keywords of the linked pages are similar to the keywords on the original page.
#3. Retrieval: Returning Relevant Results
What’s the Purpose of Search Engines?
All search engines, whether it’s Google, Yahoo or Bing have the same goal and that is to provide relevant and timely information to it’s visitors. The way search engines ensure that they are always producing quality and relevant search results is through the use of algorithms.
An algorithm is a criteria or measurable set of “ranking factors” that a search engine uses to evaluate a web page. For example, Google uses more than 200 different factors to determine how they should categorize, score and rank your web page.
This might be an over simplification, but search engines will use its algorithms to score each web page contained in its index. It’s that score that determines whether a page ranks in position 1, on page 1 which is great! or position 10, on page 10 which is not so good.
How Does SEO Fit In?
This is where SEO, which is short for “search engine optimization“ comes into play. SEO is the science or process of optimizing a webpage so that the page will rank better when search engine algorithms are applied against the page.
What Factors Do Algorithms Use?
As already mentioned, search engine algorithms help to determine the quality of a website, the overall theme and what each web page on the site is about, as well as the types of searches the website show for when a searcher is using the search engine.
Some of the factors that search engine algorithms uses to consider and evaluate a web page are the:
- Title of the page
- Content or words on the web page
- Frequency and location of keywords on a web page
- Content length
- Structure of the URLs on the website
- Page load speed
The the algorithms also analyze the way that pages link to other pages on the web. By checking how pages link to each other, a search engine (like Bing) can determine what a page is about and, if the keywords of the linked pages are similar to the keywords on the original page.
Search engines almost never share information about the algorithms they use, outside of maybe sharing some basic guidelines or best practices that a website builder or digital marketer should follow.
To find out the “Top Ranking Factors” and a complete list of all the factors, check out this article titled: “Google’s 200 Ranking Factors: The Complete List“, created by Brian Dean of backlinko.com.
The Evolution of Search Engines
A Timeline of Web Search Engines dating back from 1990 thru today (2020). The article or section does a great job of showing the evolution of search engines and the key people associated with each enhancement or change.
The Most Popular Search Engines Are:
The most popular search engines in the United States are: Google, Yahoo! and Bing. However, there are many other search engines on the Internet, serving all sorts of search purposes. Wikipedia has a list of all the known search engines in the world.
How Many Websites are on the Web?
According to WorldWideWebSize.com, as of Feb 21, 2020, there were at least four billion (6.07 billion) web pages currently being indexed by the three major search engines (Google, Yahoo and Bing).
 Image Credit: WorldWideWebSize.com, The Size of the World Wide Web, Feb 2020
Image Credit: WorldWideWebSize.com, The Size of the World Wide Web, Feb 2020
The website “Internet Live Stats“, estimates that all those web pages belong to over 1.5 billion websites.
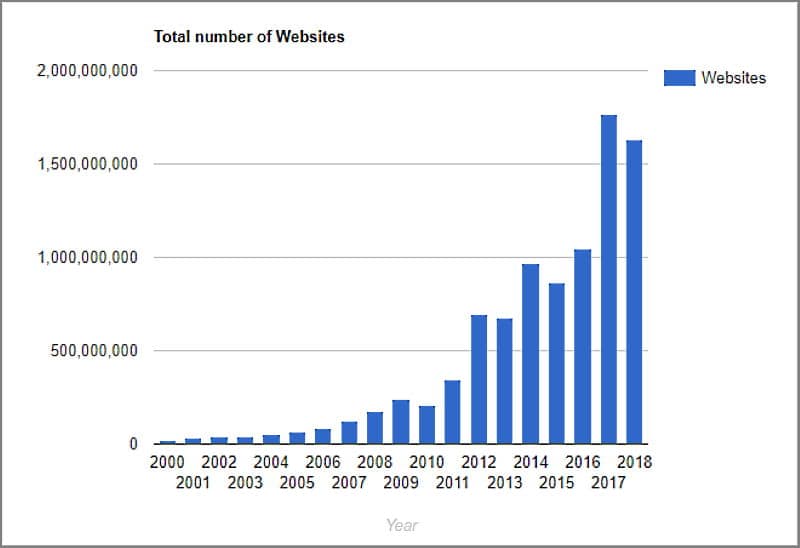 Image Credit: Internetlivestats.com, Total Number of Websites, Feb 2020
Image Credit: Internetlivestats.com, Total Number of Websites, Feb 2020
Now of course no one can really say how many websites there are for sure, but you have to admit, that’s a lot of websites, to keep track of.
People Who Read This Article, Also Read:
How and Why People Use Search Engines
What Is Search Engine Optimization?




{kind=link}
No Responses